InTDS ArchivebyGianpi ColonnaOptimizing Output File Size in Apache SparkA Comprehensive Guide on Managing Partitions, Repartition, and Coealesce OperationsAug 11, 20234Aug 11, 20234
Alireza MeskinImplementing Immutable Trie in ScalaA Trie, (also called radix tree or prefix tree) is a kind of search tree to store a dynamic set or associative array where the keys are…Feb 11, 20191Feb 11, 20191
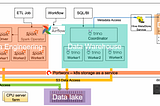
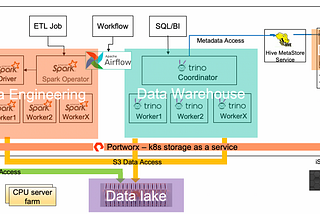
Yifeng JiangBuild an Open Data Lakehouse with Spark, Delta and Trino on S3Combining the strength of data lake and warehouse in a way that is open, simple, and runs anywhereNov 7, 20222Nov 7, 20222
InSelectFrombyAniSpark Optimization : Reducing Shuffle“Shuffling is the only thing which Nature cannot undo.” — Arthur EddingtonJul 30, 20226Jul 30, 20226
Joydip NathHow to determine Executor Core, Memory and Size for a Spark appI am assuming that you are familiar with basics of Spark programming and trying to optimize Spark for better resource management.Jun 1, 20222Jun 1, 20222
InTDS ArchivebyDavid VrbaMastering Query Plans in Spark 3.0Spark query plans in a nutshell.Jul 3, 20205Jul 3, 20205
Ajeet Singh RainaWhat is Kubernetes Operator?Kubernetes is popular due to its capability to deploy new apps at a faster pace. Thanks to “Infrastructure as data” (specifically, YAML)…Jan 11, 2022Jan 11, 2022
InGeek CulturebyJames S HockingHow to Execute a REST API call on Apache Spark the Right WayMuch of the world’s data is available via API. Learn how to consume API’s from Apache Spark the right wayAug 24, 202117Aug 24, 202117
AhmedloneTrain Sentiment Classification in 100+ languages with 90+% Accuracy with Spark NLP on Databricks…Benchmarks on different multi lingual EmbeddingsDec 10, 2021Dec 10, 2021
InCurious Data CatalogbyAditya SahuSHUFFLE: Why Am I Getting OOM Error’s !!This blog is the 4th blog in the series of 5 Most Common Spark Performance Problems . Until now we discussed spark’s Skew and Spill…Nov 26, 2021Nov 26, 2021
Vladimir PrusSpark partitioning: full controlIn this post, we’ll learn how to explicitly control partitioning in Spark, deciding exactly where each row should go. It is an important…Oct 25, 20213Oct 25, 20213
Saurabh ChawlaSpark-Radiant is now available!Spark-Radiant is Apache Spark Performance and Cost Optimizer. The product, Spark-Radiant will help optimize performance and cost…Sep 19, 2021Sep 19, 2021
Vladimir PrusSpark partitioning: the fine printIn this post, we’ll revisit a few details about partitioning in Apache Spark — from reading Parquet files to writing the results back…Sep 20, 20211Sep 20, 20211