PinnedStefano LoriRanking document similarity at scale with Spark NLPCombining the power of Spark NLP sentence embeddings and LSH approximate nearest neighbors search pipelines to catch contextual and…9 min read·Jul 2, 2023----
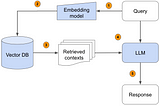
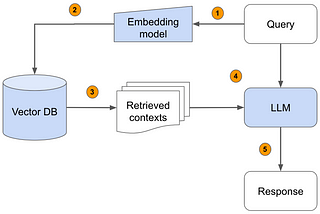
Stefano LoriSpark NLP Document Similarity Ranker as-retriever for RAG tasksBreaking news! Spark NLP (https://sparknlp.org/) gets enhanced with a new DocumentSimilarityRanker as-retriever interface for your RAG…4 min read·Mar 18, 2024----
Stefano LoriPolars is all you need: SQL chapterI just found a powerful Python SQL API for my data analysis6 min read·May 20, 2023----
Stefano Loriinspark-nlpCleaning and extracting content from HTML/XML documents using Spark NLPSpark NLP is an open-source text processing library for advanced natural language processing for the Python, Java and Scala programming…5 min read·Jan 13, 2021----
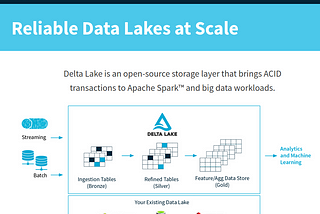
Stefano LoriReliable and serverless data ingestion using Delta Lake on AWS GlueThe Big Data scenario5 min read·Jul 21, 2020----